基于Hadoop与AI大模型的智能高校毕业生职位推荐系统设计与实现
随着高校毕业生数量逐年增加,就业市场竞争日趋激烈,传统的求职方式已难以满足学生个性化、精准化的职位匹配需求。为此,本研究设计并实现了一套集成了Hadoop大数据平台、数据可视化、网络爬虫、协同过滤推荐算法以及智能AI大模型的高校毕业生智能职位推荐系统。该系统旨在通过先进的技术手段,为毕业生提供高效、精准、个性化的职位推荐服务,同时为高校就业指导工作提供数据支持和决策参考。
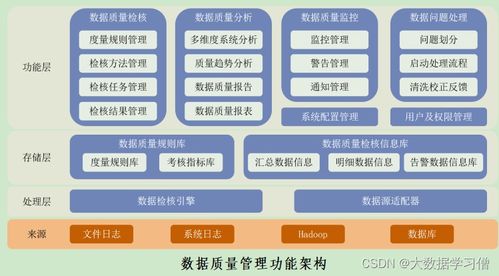
一、 系统总体架构
本系统采用分层架构设计,主要包括数据采集层、数据存储与处理层、智能推荐层和应用展示层。
- 数据采集层:利用网络爬虫技术,实时、定向地从各大招聘网站、企业官网等公开渠道爬取海量职位信息。爬虫模块具备高效、稳定、可配置的特点,能够智能识别并提取职位名称、公司信息、薪资范围、任职要求、工作地点等关键字段。系统通过接口或数据导入方式,整合高校内部的学生基本信息、学业成绩、技能证书、实习经历、求职意向等数据。
- 数据存储与处理层:作为系统的核心,采用Hadoop分布式框架构建大数据处理平台。爬取和采集的原始数据(预计初始数据集规模上万条,并持续增长)存储于HDFS分布式文件系统中。利用MapReduce编程模型或Spark计算引擎对原始数据进行清洗、去重、格式标准化和初步分析,处理非结构化与半结构化数据,为上层分析推荐提供高质量的数据基础。处理后的结构化数据可存储于HBase或数据仓库中。
- 智能推荐层:这是系统的“大脑”。基于协同过滤推荐算法,通过分析海量用户(毕业生)的历史行为数据(如浏览、收藏、投递记录)和项目(职位)属性,计算用户之间或职位之间的相似度,从而为目标用户推荐其可能感兴趣的职位。为进一步提升推荐的精准度和深度理解能力,本系统创新性地集成了智能AI大模型(如经过微调的开源大语言模型)。大模型能够深度解析职位描述中的复杂语义信息(如技能要求、公司文化倾向)和学生的简历文本,进行更细腻的特征提取与语义匹配,理解潜在需求,甚至生成个性化的求职建议或简历优化提示,实现超越传统协同过滤的智能推荐与交互。
- 应用展示层:面向毕业生用户,提供友好的Web或移动端交互界面。系统将推荐结果、职位详情、匹配度分析等以直观的形式呈现。关键亮点在于集成了数据可视化模块,利用ECharts、D3.js等工具,将行业需求趋势、薪资分布、技能热度、个人竞争力雷达图等以图表、仪表盘的形式动态展示,帮助毕业生宏观把握就业市场,明确自身定位。为管理员(如高校就业中心)提供后台管理、数据统计、报告生成等功能。
二、 核心实现技术
- Hadoop生态应用:HDFS保障了海量招聘数据与学生数据的安全可靠存储;MapReduce/Spark实现了高效的数据批处理与特征计算,为推荐算法提供实时或离线的数据支持。
- 混合推荐策略:结合基于用户的协同过滤、基于项目的协同过滤以及基于内容的推荐,并引入AI大模型的语义理解能力,形成混合推荐模型,有效缓解数据稀疏性和冷启动问题,提高推荐覆盖率和准确性。
- 智能AI大模型集成:利用预训练的大语言模型,通过Prompt工程或微调(Fine-tuning)技术,使其适配职位推荐场景。模型能够完成:职位信息摘要、技能关键词增强提取、简历与职位描述的多维度匹配度评分、生成推荐理由及个性化求职建议等任务。
- 动态数据可视化:前端与后端数据处理结果联动,实现可视化图表的动态更新与交互查询,使数据洞察一目了然。
三、 项目成果与资源
本项目将产出全套高质量资源,助力学术研究与实践应用:
- 精品源码:提供完整、结构清晰、注释详尽的系统前后端源代码,遵循良好的编程规范,具备高可读性和可扩展性,便于二次开发与研究复现。
- 精品论文:撰写系统性的学术论文,详细阐述研究背景、相关技术综述、系统设计原理、核心算法实现与优化、实验设计与结果分析(如推荐准确率、召回率、F1值等指标对比),以及对未来工作的展望。
- 上万数据集:提供经过清洗和标注的初始数据集,包含职位信息、模拟学生画像及交互行为数据,为算法训练与测试提供坚实基础。
- 答辩PPT:制作内容详实、逻辑清晰、视觉美观的毕业答辩演示文稿,涵盖项目背景、技术选型、系统演示、创新点与项目价值,完美适用于毕业设计答辩场景。
- 计算机系统服务:系统设计充分考虑部署与运维,可打包为完整的计算机系统服务方案,支持在校园服务器或云平台上进行部署,为高校提供切实可用的就业服务平台。
四、 与展望
本系统深度融合大数据技术、人工智能前沿与可视化交互,构建了一个智能化、数据驱动的高校毕业生职位推荐服务平台。它不仅提升了职位匹配的效率和精准度,还通过数据洞察赋能学生职业规划与高校就业服务。可考虑引入实时流处理技术(如Flink)处理更动态的行为数据,探索多模态大模型处理视频招聘介绍等更丰富的信息,并持续优化算法模型,以更好地服务于高校毕业生就业这一重大民生工程。
如若转载,请注明出处:http://www.chinaapmdata.com/product/56.html
更新时间:2026-06-19 16:33:53